
一种基于多尺度卷积核和超事件模块的单阶段动作定位方法,由提取视频时空特征、特征卷积与降维、构建主干分支和学习超事件表达、构建定位和分类分支、获取预测结果步骤组成。其中主干分支用多尺度深度可分离时序卷积层捕获视频中动作时间跨度的多样性并生成多尺度特征,采用超事件模块学习输入视频的时序结构和上下文信息得到对应的超事件表达,超事件表达与经反卷积操作生成的定位和分类分支中的多尺度特征图融合经定位和分类预测层获取预测结果。本发明与现有的主流单阶段动作定位方法相比,能更好地检测视频中不同时间跨度的动作,学习得到的超事件表达提高了动作定位准确率,可用于视频中动作片段提取。
1.一种基于多尺度卷积核和超事件模块的单阶段动作定位方法,其特征在于由下述步骤组成:
(1)提取视频时空特征
将视频抽取为图像帧序列和光流帧序列,图像帧序列和光流帧序列分别采用滑动窗口方法以窗口大小1024帧、步长256帧划分为帧序列片段,送入三维卷积网络提取得到128×1204维的视频时空特征;
(2)特征卷积与降维
对提取的视频时空特征经两层一维时序卷积层对特征进行卷积操作,经第一层最大池化层进行池化操作将特征时间维度降低一半得到64×1024维的视频时空特征,经维度调整后得到64×1×1×1024维的输出视频时空特征;
(3)构建主干分支和学习超事件表达
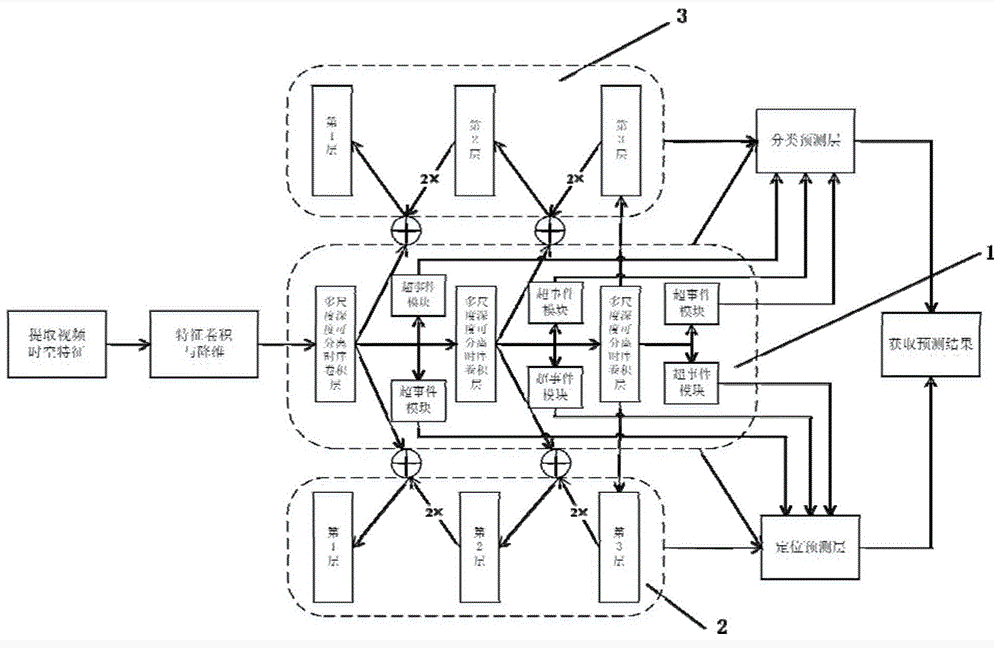
将3个多尺度深度可分离时序卷积层串连构建成主干分支(1),输出视频时空特征经3个串连的多尺度深度可分离时序卷积层生成32×1×1×1280、16×1×1×1600、8×1×1×2000三种不同尺度的视频时空特征,每个多尺度深度可分离时序卷积层对应输出一种尺度的视频时空特征;每个多尺度深度可分离时序卷积层的输出视频时空特征经其后的超事件模块学习视频时空特征对应的超事件表达,超事件表达中包含输入视频的时序结构和上下文信息;
(4)构建定位和分类分支
1)主干分支(1)中3个多尺度深度可分离时序卷积层输出视频时空特征经卷积核大小为1×1×1的时序卷积层将特征通道数扩大至2480后得到时间维度为32、16、8,通道数为2480的32×1×1×2480、16×1×1×2480、8×1×1×2480的三种输出视频时空特征;
2)使用一维时序卷积层对三种输出视频时空特征进行卷积操作;主干分支(1)中第3层输出视频时空特征经卷积操作后生成8×1×1×2480维的视频时空特征作为定位分支(2)和分类分支(3)中第3层的视频时空特征;
3)第3层的视频时空特征经反卷积层将时间维度扩大2倍得到16×1×1×2480维的视频时空特征,和主干分支(1)第2层16×1×1×2480维的视频时空特征进行通道相加生成定位分支(2)和分类分支(3)中第2层的视频时空特征;第2层的视频时空特征用相同的方法得到32×1×1×2480维的视频时空特征,和主干分支(1)第1层32×1×1×2480维的视频时空特征进行通道相加生成定位分支(2)和分类分支(3)中第1层的视频时空特征;
(5)获取预测结果
1)为3个分支中每层视频时空特征对应的每个时间维度设定长宽比RS为{0.5,0.75,1,1.5,2}的动作提议,每个分支的三层输出视频时空特征对应的尺度BS为{1/16,1/8,1/4},长宽比RS与尺度BS的乘积得到3个分支中每层视频时空特征对应的动作提议的时长;
2)训练和测试时将定位分支(2)和分类分支(3)三层视频时空特征分别与主干分支(1)中学习得到的超事件表达按通道先后顺序拼接送入分类预测层和定位预测层生成预测结果;对于每个动作提议,由下式得到预测结果:


式中μC和μW分别为设定的中心点和宽度,α1和α2为权重,ΔC和ΔW分别为预测的提议中心和宽度坐标偏移值,![]() 和
和![]() 为预测的动作提议中心和宽度;
为预测的动作提议中心和宽度;
3)将预测的动作提议中心和宽度在测试时,使用阈值为0.2的非极大值抑制策略去除冗余,得到预测结果。
2.根据权利要求1所述的基于多尺度卷积核和超事件模块的单阶段动作定位方法,其特征在于所述的特征卷积与降维步骤(2)为:对提取的视频时空特征经两层卷积核大小为5、步长为1的一维时序卷积层对特征进行卷积操作,经第一层池化核大小为4、步长为2的最大池化层进行池化操作将特征时间维度降低一半得到64×1024维的视频时空特征,经维度调整后得到64×1×1×1024维的输出视频时空特征。
3.根据权利要求1所述的基于多尺度卷积核和超事件模块的单阶段动作定位方法,其特征在于在构建主干分支(1)和学习超事件表达步骤(3)中,所述的生成32×1×1×1280、16×1×1×1600、8×1×1×2000三种不同尺度的视频时空特征的方法如下:
1)将64×1×1×1024维的视频时空特征输入第1个多尺度深度可分离时序卷积层,按特征通道将输出视频时空特征分为4组,每组视频时空特征维度为64×1×1×256;
2)使用时序卷积模块对每组输入视频时空特征进行卷积操作,时序卷积模块由5个并行的分支构成,其中第1个分支使用池化核大小为2、步长为1的最大池化层对输入视频时空特征进行池化操作,第2、3、4个分支分别使用卷积核大小为3、5、7的一维时序卷积层对视频时空特征进行卷积操作;在每个分支后连接卷积核大小为1×1的二维卷积层,5个分支的输出视频时空特征按分支的先后顺序依次拼接得到每组输入视频时空特征对应的输出视频时空特征;
3)4组输出视频时空特征按分组的先后顺序依次拼接,打乱特征通道顺序来交互不同通道间的信息;
4)特征通道顺序打乱后的视频时空特征经池化核大小为2,步长为1的最大池化层进行池化操作将特征时间维度降低一半,得到第1个多尺度深度可分离时序卷积层32×1×1×1280维的输出视频时空特征;
5)重复2次步骤1)~4),生成主干分支(1),即三种不同尺度的视频时空特征。
4.根据权利要求1所述的基于多尺度卷积核和超事件模块的单阶段动作定位方法,其特征在于在构建主干分支(1)和学习超事件表达步骤(3)中,所述的超事件模块学习视频时空特征对应的超事件表达方法如下:
1)每2~5个柯西分布构建成1个时序结构滤波器Fm,共构建成2~5个时序滤波器Fm;每个时序结构滤波器Fm由下式确定:



式中t为某一时刻、t∈{1,2,...,T},T是多尺度深度可分离时序卷积层输出视频时空特征时间维度、为有限的正整数;n为某一时序结构滤波器、n∈{1,2,...,N},N是时序结构滤波器的个数、为有限的正整数;xn和γn分别为具体某一柯西分布的中心位置和宽度,![]() 和
和![]() 分别为多个柯西分布中心位置和宽度的集合,tanh为激活函数,exp为指数函数,Zn为归一化常数;
分别为多个柯西分布中心位置和宽度的集合,tanh为激活函数,exp为指数函数,Zn为归一化常数;
2)将得到的2~5个时序结构滤波器Fm与多尺度深度可分离时序卷积层的输出视频时空特征进行矩阵相乘得到中间特征,中间特征与通过注意力机制学习得到的的软注意力权重,进行矩阵相乘,得到超事件表达SC,具体方法如下:


式中M为时序结构滤波器Fm的个数,T为多尺度深度可分离时序卷积层输出视频时空特征时间维度,Vt表示多尺度深度可分离时序卷积层输出视频时空特征,Wc,m和Wc,k分别为第m个和第k个时序结构滤波器Fm对应的权重,Ac,m表示第m个时序结构滤波器Fm对应的软注意力权重,exp为指数函数。
5.根据权利要求4所述的基于多尺度卷积核和超事件模块的单阶段动作定位方法,其特征在于:在步骤1)中,每3个柯西分布构建成1个时序结构滤波器Fm,共构建成3个时序滤波器Fm。
6.根据权利要求1所述的基于多尺度卷积核和超事件模块的单阶段动作定位方法,其特征在于所述的构建定位和分类分支步骤(4)的步骤2)为:使用卷积核大小为3、步长为1的一维时序卷积层对三种输出视频时空特征进行卷积操作;主干分支中第3层输出视频时空特征经卷积操作后生成8×1×1×2480维的视频时空特征作为定位分支和分类分支中第3层的视频时空特征;
所述的构建定位和分类分支步骤(4)的步骤3)为:第3层的视频时空特征经卷积核大小为4、步长为2的反卷积层将时间维度扩大2倍得到16×1×1×2480维的视频时空特征,和主干分支第2层16×1×1×2480维的视频时空特征进行通道相加生成定位分支和分类分支中第2层的视频时空特征;第2层的视频时空特征用相同的方法得到32×1×1×2480维的视频时空特征,和主干分支第1层32×1×1×2480维的视频时空特征进行通道相加生成定位分支和分类分支中第1层的视频时空特征。
请联系平台。




