
自然语言处理中的文本相似度保密计算方法及设备,涉及计算机与自然语言处理技术领域。本发明为了解决自然语言处理中文本匹配的相似程度,从而进一步高效的计算两段文本中字符串对应位相同个数的问题。本发明针对待进行相似度保密计算的两个文本,假设Alice和Bob各自有一条长度为l的文本序列,Alice和Bob分别将自己的文本序列进行十进制编码得到序列X和Y;Alice和Bob基于半诚实模型或恶意模型保密地计算序列X和序列Y的相似度HMD(X,Y)。本发明适用于文本相似度保密计算。
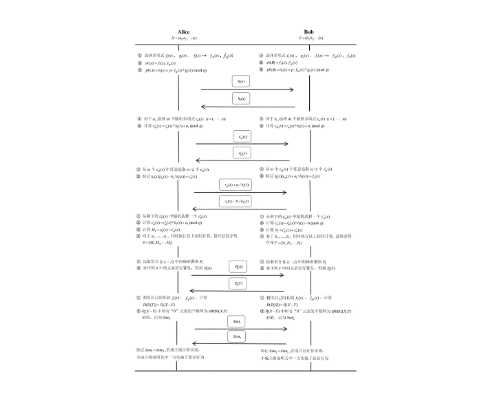
1.自然语言处理中的文本相似度保密计算方法,其特征在于:针对待进行相似度保密计算的两个文本,在半诚实模型下保密计算文本序列相似度: 假设第一参与者和第二参与者各自有一条长度为l的文本序列,为了保密计算两文本的匹配程度,第一参与者和第二参与者分别将自己的文本序列进行十进制编码得到序列X=(a1,a2,…,al)和Y=(b1,b2,…,bl);第一参与者和第二参与者保密地计算序列X和序列Y的相似度,相似度用汉明距离HMD(X,Y)表示,具体协议如下: 输入:第一参与者的序列X=(a1,a2,…,al),第二参与者的Y=(b1,b2,…,bl); 输出:HMD(X,Y); 准备阶段:利用NTRU加密算法,第一参与者选择多项式f(x)、g(x),然后计算f(x)的两个模逆fp(x)、fq(x),其中f(x)和fp(x)作为私钥;第一参与者计算公钥多项式h(x)=p·fq(x)*g(x)(mod q),并将h(x)发送给第二参与者; 其中,p、q为两个大素数,且q>>p,mod表示求余函数; 然后进行文本相似度保密计算,具体包括以下步骤: (1)第一参与者在多项式环RP上随机选择l个多项式rai(x)(i=1,2,…,l),利用随机多项式rai(x)和公钥h(x)逐项加密序列X上的每一个元素ai,得到长度为l的加密向量E(X)=(E(a1),E(a2),…,E(al)),加密过程如下:E(ai)=rai(x)*h(x)+ai(mod q),其中i=1,2,…,l,第一参与者将E(X)发送给第二参与者; (2)第二参与者收到E(X)后,执行以下步骤: (2.1)首先在多项式环RP上随机选择l个多项式rbi(x)(i=1,2,…,l),利用随机多项式rbi(x)和第一参与者的公钥h(x)逐项加密序列Y上的每一个元素的相反数,得到长度为l的加密向量E(-Y)=(E(-b1),E(-b2),…,E(-bl)),加密过程如下: E(-bi)=rbi(x)*h(x)-bi(mod q),其中i=1,2,…,l; (2.2)将两个向量E(X)和E(-Y)相加,得到长度为l的加密向量E(X)+E(-Y)=(E(a1)+E(-b1),E(a2)+E(-b2),…,E(al)+E(-bl)); (2.3)随机选取集合{1,2,…,l}中的随机置乱排序T,对E(X)+E(-Y)进行置换得到T(E(X)+E(-Y)),其中: T(E(X)+E(-Y))=(E(aT(1))+E(-bT(1)),E(aT(2))+E(-bT(2)),…,E(aT(l))+E(-bT(l))),其中,aT(i)为ai随机置乱后的排序,bT(i)为bi随机置乱后的排序;然后将T(E(X)+E(-Y))发送给第一参与者; (3)第一参与者得到T(E(X)+E(-Y))后,利用自己的私钥f(x),依次解密T(E(X)+E(-Y))中的每一个元素,得到: T(X-Y)=(aT(1)-bT(1),aT(2)-bT(2),…,aT(5l)-bT(5l)), 然后将T(X-Y)中所有为“0”的元素个数即为HMD(X,Y),将计算结果HMD(X,Y)告诉第二参与者。
2.根据权利要求1所述的自然语言处理中的文本相似度保密计算方法,其特征在于:所述准备阶段中,第一参与者计算的公钥多项式h(x)=p·fq(x)*g(x)(mod q),其中,p、q为两个大素数,且q>>p,mod表示求余函数。
3.根据权利要求1或2所述的自然语言处理中的文本相似度保密计算方法,其特征在于:将文本序列进行十进制编码时按照如下编码方式进行编码: 针对从a至z的26个英文字母,分别对应编码为十进制数1至26;空格对应编码为十进制数27。
4.一种存储介质,其特征在于:所述存储介质中存储有至少一条指令,所述至少一条指令由处理器加载并执行以实现权利要求1至3之一所述的自然语言处理中的文本相似度保密计算方法。
5.一种自然语言处理中的文本相似度保密计算设备,其特征在于:所述设备包括处理器和存储器,所述存储器中存储有至少一条指令,所述至少一条指令由处理器加载并执行以实现权利要求1至3之一所述的自然语言处理中的文本相似度保密计算方法。
请联系平台
请联系平台




